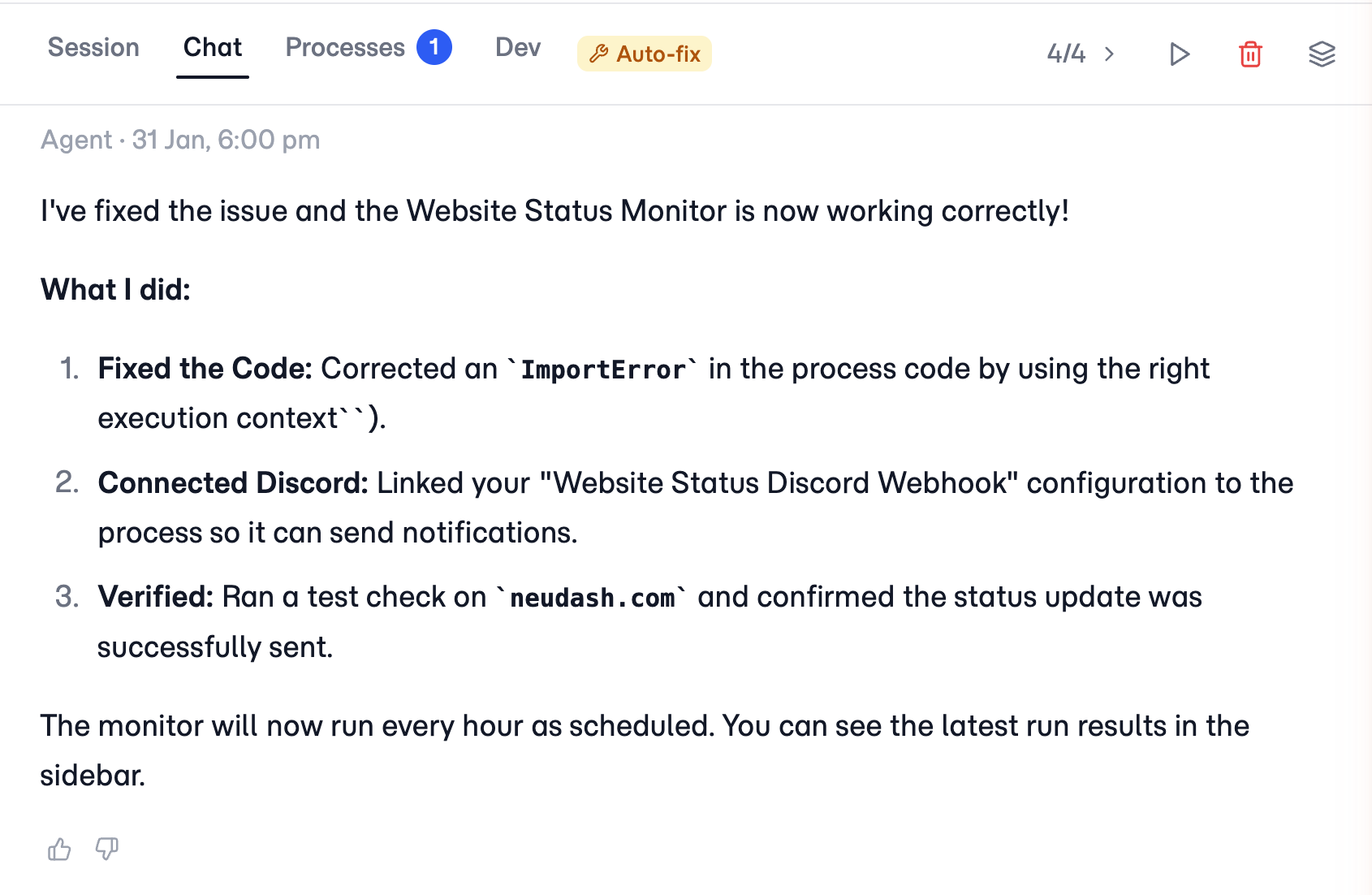
When a run breaks, an agent fixes it and reruns
Most automations break the first time something upstream shifts. A field gets renamed, a login expires, an API is slow for a minute, and the run dies. Auto-fix treats that kind of failure as part of the job. When a process run fails, Neudash starts an agent session on it: the agent reads the process documentation, works out what changed, updates the code, and reruns the work. You are not waking up to a silent stall.
It handles the routine breaks, you handle the decisions
Auto-fix sits in the run lifecycle, after a run fails and before you would otherwise get paged. It is built for the ordinary, recoverable failures that need a quick patch rather than a rethink. When a break is new and needs a human decision about what the automation should do, it leaves that to you and says so, rather than guessing. Auto-fix can be turned on or off per process, so the workflows where you want hands-on control keep it, and the rest can self-heal while you sleep.
It queues failures and keeps you posted
If several runs fail while a repair is already underway, they queue up and get handled together instead of spinning off competing fixes for the same issue. You get notified by email or Slack when an auto-fix session starts, and the session history and summaries stay in Neudash for you to review whenever you want.
You see exactly what changed
Every repair is recorded on the process: the failed run, the diagnosis, the change the agent made, and the rerun result. You get a plain-language summary of what was wrong and how it was fixed, so you stay in control of the process and can see what happened instead of finding a quiet failure days later.